「Python3爬虫」统计博客代码量
好奇了一下,一年多的OI生涯自己写了多少代码,就写个了爬虫统计
做法很暴力,直接枚举文章的编号,由于wordpress编号不连续,爬了很多404页面,以后要考虑遍历sitemap
因为我文章的代码都是用Crayon Syntax Highlighter实现高亮的,都是以</textarea>结束,比较容易能用正则匹配出来
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# 统计博客hzwer.com上的代码行数 __author__ = 'hzwer' # -*- coding: utf-8 -*- import re from urllib.request import * home = 'http://hzwer.com/' tot = 0 page = 0 for i in range(1, 8000): try: url = home + str(i) + '.html' request = Request(url) response = urlopen(request) content = response.read().decode("UTF-8").replace("\r\n", "\n") except: pass else: pattern = re.compile('-webkit-tab-size:4; tab-size:4; font-size: 15px !important; line-height: 16px !important;">\n(.*?)</textarea>', re.S) code = re.findall(pattern, content) if(code): length = 0 for j in code: length = length + len(j.splitlines()) tot += length print('url: {} {}行代码,合计{}行代码'.format(url, length, tot)) page = page + 1 print('共{}个页面,{}行代码'.format(page, tot)) |
运行了几小时,结果如下:
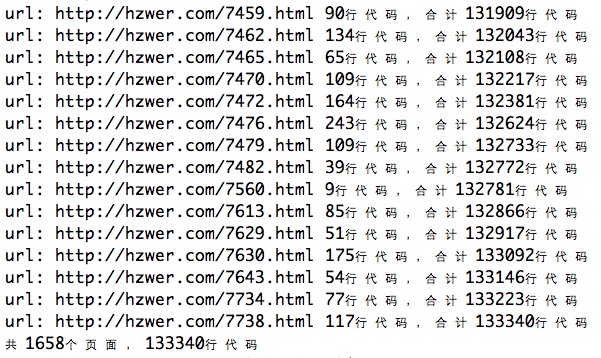
跟我估计的差不多,加上基础题大概只有14w的样子,与神犇们相距甚远,自然滚粗
140k行给跪……我Github里记录的一共是28k行……
跪跪跪..不过我感觉可以先从mysql里获取有效的文章id..然后统计..因为post_id这个东西是版本控制+有效文章+草稿+媒体..但是在phpmyadmin里很好统计..
对。。。
黄学长,请问网络流24题第八道机器人路径规划怎么搞?急求,大家都没有想法,谢谢了!
有论文http://wenku.baidu.com/view/ec2c5a7616fc700abb68fc8f
跪orzzzzzzzz
(另强力安利黄学长用requests库写…不要用urllib这种落后的东西了…
下次注意QAQ
Orz……
140k嘛,实际上写个应用这都不算什么的。。。OI就是天文数字了
Orz
跪跪跪
跪烂