「强化学习」DDPG 的 PyTorch 实现
博客文章被回档了一个月,本文重发
一起实现的用来做强化学习实验的框架
目前还在继续完善,实现一些算法或者技巧
相比之前我们 Learning to run 比赛乱得可怕的代码,目前的架构、兼容性和实现程度还比较可以接受
默认参数在CartPole,Pendulum,BipedalWalker等环境中都有比较不错的表现
在我的 mac 上训练 CartPole 需要这么些行代码「一键完成 CartPole」
|
1 2 3 4 5 6 7 8 9 10 11 12 |
$ conda create --name pybullet python=3.6 $ source source activate pybullet // 建议使用 anaconda $ conda install pytorch $ pip install gym $ pip install tensorboardX // 以上是安装依赖 $ git clone https://github.com/megvii-rl/pytorch-gym $ cd pytorch-gym $ python main.py --env CartPole-v0 --discrete --debug --vis // --discrete 是把输出取 argmax 强行离散 |
进一步了解移步 https://github.com/megvii-rl/pytorch-gym
下一步想把我们的一些发现再做做实验 https://arxiv.org/pdf/1712.08987.pdf
本机 CartPole-v0,随机 warmup 1000 step 后非常快地完成
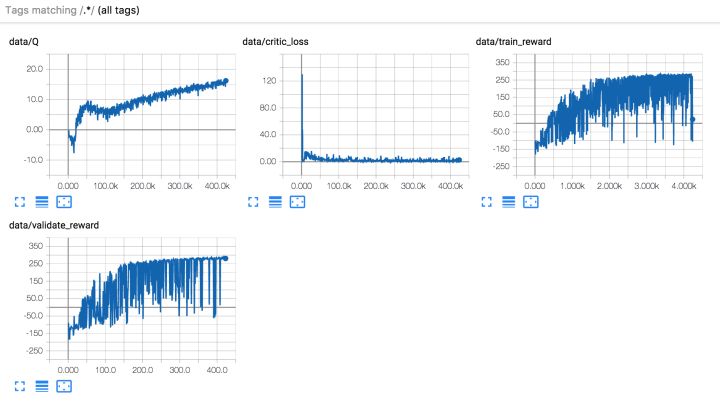
在服务器的 gpu 上训 BipedalWalker-v2,两小时的曲线
Subscribe